Вольный перевод Oops! Debugging Kernel Panics
Небольшой обзор причин, приводящих к kernel panic, и утилит, которые помогут получить больше информации.
Работая в среде с ядром Linux, как часто вы видели kernel panic? Когда это случается, система находится в повреждённом состоянии пока вы её не перезагрузите. И даже после восстановления работоспособности остаётся вопрос: почему это произошло? Вы можете даже не догадываться, в чём причина. Тем не менее, ответ может быть найден, и это руководство постарается помочь вам найти первопричину kernel panic и устранить её.
Начнём с обзора утилит kexec и kdump. kexec позволяет загружать другое ядро из текущего (и работающего), а kdump — это механизм создания crash dump’ов ядра, основанный на kexec.
Установка необходимых пакетов
Первое и самое важное, ядро должно содержать эти компоненты, статически встроенные в его образ:
CONFIG_RELOCATABLE=y
CONFIG_KEXEC=y
CONFIG_CRASH_DUMP=y
CONFIG_DEBUG_INFO=y
CONFIG_MAGIC_SYSRQ=y
CONFIG_PROC_VMCORE=yПроверить эти значения можно в конфигурационном файле ядра, для стандартной установки Debian/Ubuntu:
$ grep "CONFIG_ЗНАЧЕНИЕ" /boot/config-`uname -r`Убедитесь, что ваша система в актуальном состоянии и имеет старшие версии пакетов из доступных.
# apt update && apt upgradeУстановите следующие пакеты (я сейчас использую Debian, но то же должно работать и для Ubuntu):
# apt install gcc make binutils linux-headers-`uname -r` kdump-tools crash `uname -r`-dbgЗамечание: имена пакетов могут отличаться в разных дистрибутивах
Во время установки вам будет предложено включить перехват перезагрузок посредством kexec (вы можете ответить на это как пожелаете, но я выбрал «No», см. Изображение 2)
И включить kdump во время загрузки системы, отвечайте «Yes» (Изображение 3).
Конфигурация kdump
Откройте файл /etc/default/kdump-tools, в самом верху вы должны увидеть таки строки:
USE_KDUMP=1
#KDUMP_SYSCTL="kernel.panic_on_oops=1"В дальнейшем, мы напишим собственный модуль, который будет провоцировать состояние ядра OOPS. Для того, чтобы kdump собирал и сохранял состояние системы для анализа, необходимо ядру запаниковать на OOPS. Для этого нужно раскомментировать строчку, начинающуюся с KDUMP_SYSCTL:
USE_KDUMP=1
KDUMP_SYSCTL="kernel.panic_on_oops=1"Для первоначального тестирование системы нужно включить SysRq, есть несколько способов сделать это, но я выберу тот, который требует перезагрузки системы для активации этой функциональности. Откройте файл /etc/sysctl.d/99-sysctl.conf и убедитесь, что следующая строчка (располагается ближе к концу файла) раскомментирована:
kernel.sysrq=1Теперь откройте файл /etc/default/grub.d/kdump-tools.defaul, там будет одна строчка на подобии этой:
GRUB_CMDLINE_LINUX_DEFAULT="$GRUB_CMDLINE_LINUX_DEFAULT crashkernel=384M-:128M"Замените crashkernel=384M-:128M на crashkernel=128M.
Обновите конфигурационный файл GRUB2, чтобы изменения вступили в силу:
# update-grubПосле чего перезагрузите систему.
Проверка работы kdump
После перезагрузки, в dmesg будут похожие строки:
# dmesg |grep -i crash
[ 0.000000] Command line: BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-a0d8-a7533620f6fa ro quiet crashkernel=128M
[ 0.000000] Reserving 128MB of memory at 720MB for crashkernel (System RAM: 4095MB)
[ 0.000000] Kernel command line: BOOT_IMAGE=/boot/ vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-a0d8-a7533620f6fa ro quiet crashkernel=128MА в ядре будут включены такие параметры («1» значит включён):
# sysctl -a|grep kernel|grep -e panic_on_oops -e sysrq
kernel.panic_on_oops = 1
kernel.sysrq = 1Сервис kdump должен быть запущен:
# systemctl status kdump-tools.service
kdump-tools.service - Kernel crash dump capture service
Loaded: loaded (/lib/systemd/system/kdump-tools.service; enabled; vendor preset: enabled)
Active: active (exited) since Tue 2019-02-26 08:13:34 CST; 1h 33min ago
Process: 371 ExecStart=/etc/init.d/kdump-tools start (code=exited, status=0/SUCCESS)
Main PID: 371 (code=exited, status=0/SUCCESS)
Tasks: 0 (limit: 4915)
CGroup: /system.slice/kdump-tools.service
Feb 27 08:13:34 deb-panic systemd[1]: Starting Kernel crash dump capture service...
Feb 27 08:13:34 deb-panic kdump-tools[371]: Starting kdump-tools: loaded kdump kernel.
Feb 27 08:13:34 deb-panic kdump-tools[505]: /sbin/kexec -p --command-line="BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64 root=
Feb 27 08:13:34 deb-panic kdump-tools[506]: loaded kdump kernel
Feb 27 08:13:34 deb-panic systemd[1]: Started Kernel crash dump capture service.А аварийное ядро должен быть загружено (в область памяти 128Мб, которую вы задали раньше):
$ cat /sys/kernel/kexec_crash_loaded
1Так вы можете проверить свою конфигурацию kdump:
# kdump-config show
DUMP_MODE: kdump
USE_KDUMP: 1
KDUMP_SYSCTL: kernel.panic_on_oops=1
KDUMP_COREDIR: /var/crash
crashkernel addr: 0x2d000000
/var/lib/kdump/vmlinuz: symbolic link to /boot/vmlinuz-4.9.0-8-amd64
kdump initrd:
/var/lib/kdump/initrd.img: symbolic link to /var/lib/kdump/initrd.img-4.9.0-8-amd64
current state: ready to kdump
kexec command:
/sbin/kexec -p --command-line="BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-a0d8-a7533620f6fa ro quiet irqpoll nr_cpus=1 nousb systemd.unit=kdump-tools.service ata_piix.prefer_ms_hyperv=0" --initrd=/var/lib/kdump/initrd.img /var/lib/kdump/vmlinuzДавайте его протестируем без реального его запуска:
# kdump-config test
USE_KDUMP: 1
KDUMP_SYSCTL: kernel.panic_on_oops=1
KDUMP_COREDIR: /var/crash
crashkernel addr: 0x2d000000
kdump kernel addr:
kdump kernel:
/var/lib/kdump/vmlinuz: symbolic link to /boot/vmlinuz-4.9.0-8-amd64
kdump initrd:
/var/lib/kdump/initrd.img: symbolic link to /var/lib/kdump/initrd.img-4.9.0-8-amd64
kexec command to be used:
/sbin/kexec -p --command-line="BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-a0d8-a7533620f6fa ro quiet irqpoll nr_cpus=1 nousb systemd.unit=kdump-tools.service ata_piix.prefer_ms_hyperv=0" --initrd=/var/lib/kdump/initrd.img /var/lib/kdump/vmlinuzМомент истины
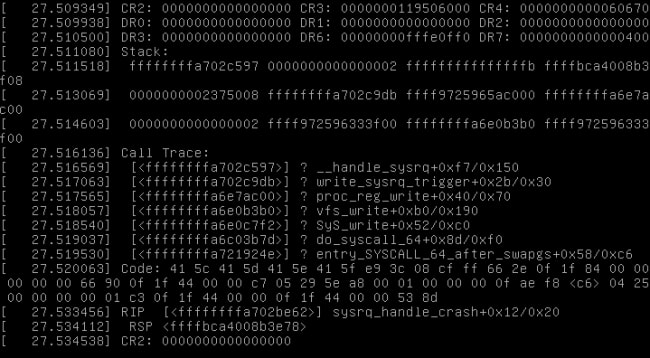
Теперь, когда kdump настроен, необходимо его протестировать, и лучший способ — это спровоцировать падение ядра с помощью SysRq. Если ваше ядро собрано с поддержкой SysRq, положить ядро так же просто, как напечатать в консоле:
# echo "c" | tee -a /proc/sysrq-triggerЧто должно произойти? Вы увидите панику/падение ядра, похожу на Изображение 1. После падения, ядро, загруженное kexec, соберёт всю информаци о состоянии системы: памяти, процессора, dmesg, загруженные модули и много другое. Эти данные будут доступны для анализа в какой-то подпапке /var/chash/. После сбора данных, система автоматически перезагрузится обратно в рабочее состояние.
Что дальше?
Теперь у вас есть аварийные файлы, расположенные в папке /var/crash:
$ cd /var/crash/
$ ls
201902271006 kexec_cmd
$ cd 201902271006/Кроме того, перед тем как открыть аварийный файл, нужно установить исходный код ядра:
# apt source linux-image-`uname -r`Раньше вы установили отладочную версию ядра. В ней не вырезаны отладочные символы, которые требуются для этого типа отладки. Теперь вам нужно это ядро. Откройте аварийный файл с помощью утилиты crash:
# crash dump.201902271006 /usr/lib/debug/vmlinux-4.9.0-8-amd64Когда всё загрузится, обзор kernel panic отобразится на экране:
KERNEL: /usr/lib/debug/vmlinux-4.9.0-8-amd64
DUMPFILE: dump.201902261006 [PARTIAL DUMP]
CPUS: 4
DATE: Tue Feb 26 10:07:21 2019
UPTIME: 00:04:09
LOAD AVERAGE: 0.00, 0.00, 0.00
TASKS: 100
NODENAME: deb-panic
RELEASE: 4.9.0-8-amd64
VERSION: #1 SMP Debian 4.9.144-3 (2019-02-02)
MACHINE: x86_64 (2592 Mhz)
MEMORY: 4 GB
PANIC: "sysrq: SysRq : Trigger a crash"
PID: 563
COMMAND: "tee"
TASK: ffff88e69628c080 [THREAD_INFO: ffff88e69628c080]
CPU: 2
STATE: TASK_RUNNING (SYSRQ)Заметьте причину паники ядра: sysrq: SysRq : Trigger a crash. Кроме этого, программу, которая привела к падению: tee. Ничего удивительного, ведь вы сами сделали это 🙂
Если вы запустите трассировку стека функций, которые привели к падению, то увидите что-то такое (код работал на 2 ядре процессора):
crash> bt
PID: 563 TASK: ffff88e69628c080 CPU: 2 COMMAND: "tee"
#0 [ffffa67440b23ba0] machine_kexec at ffffffffa0c53f68
#1 [ffffa67440b23bf8] __crash_kexec at ffffffffa0d086d1
#2 [ffffa67440b23cb8] crash_kexec at ffffffffa0d08738
#3 [ffffa67440b23cd0] oops_end at ffffffffa0c298b3
#4 [ffffa67440b23cf0] no_context at ffffffffa0c619b1
#5 [ffffa67440b23d50] __do_page_fault at ffffffffa0c62476
#6 [ffffa67440b23dc0] page_fault at ffffffffa121a618
[exception RIP: sysrq_handle_crash+18]
RIP: ffffffffa102be62 RSP: ffffa67440b23e78 RFLAGS: 00010282
RAX: ffffffffa102be50 RBX: 0000000000000063 RCX: 0000000000000000
RDX: 0000000000000000 RSI: ffff88e69fd10648 RDI: 0000000000000063
RBP: ffffffffa18bf320 R8: 0000000000000001 R9: 0000000000007eb8
R10: 0000000000000001 R11: 0000000000000001 R12: 0000000000000004
R13: 0000000000000000 R14: 0000000000000000 R15: 0000000000000000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#7 [ffffa67440b23e78] __handle_sysrq at ffffffffa102c597
#8 [ffffa67440b23ea0] write_sysrq_trigger at ffffffffa102c9db
#9 [ffffa67440b23eb0] proc_reg_write at ffffffffa0e7ac00
#10 [ffffa67440b23ec8] vfs_write at ffffffffa0e0b3b0
#11 [ffffa67440b23ef8] sys_write at ffffffffa0e0c7f2
#12 [ffffa67440b23f38] do_syscall_64 at ffffffffa0c03b7d
#13 [ffffa67440b23f50] entry_SYSCALL_64_after_swapgs at ffffffffa121924e
RIP: 00007f3952463970 RSP: 00007ffc7f3a4e58 RFLAGS: 00000246
RAX: ffffffffffffffda RBX: 0000000000000002 RCX: 00007f3952463970
RDX: 0000000000000002 RSI: 00007ffc7f3a4f60 RDI: 0000000000000003
RBP: 00007ffc7f3a4f60 R8: 00005648f508b610 R9: 00007f3952944480
R10: 0000000000000839 R11: 0000000000000246 R12: 0000000000000002
R13: 0000000000000001 R14: 00005648f508b530 R15: 0000000000000002
ORIG_RAX: 0000000000000001 CS: 0033 SS: 002bВ этой трассировке вы можете узнать символьный адрес хранящегося в указателе возврата инструкций (Return Instruction Pointer (RIP)): ffffffffa102be62. Давайте посмотрим на символ по этому адресу:
crash> sym ffffffffa102be62
ffffffffa102be62 (t) sysrq_handle_crash+18 ./debian/build/build_amd64_none_amd64/./drivers/tty/sysrq.c: 144Подождите! Получается, что исключение было вызвано на 144 строке в файле drivers/tty/sysrq.c, внутри функции sysrq_handle_crash. Хмм… Интересно, что же происходит в этом файле ядра (вот зачем вы установили пакет исходного кода ядра недавно). Перейдём в папку /usr/src и распакуем пакет исходго кода ядра:
$ cd /usr/src
$ ls
linux_4.9.144-3.debian.tar.xz linux_4.9.144.orig.tar.xz linux-headers-4.9.0-8-common
linux_4.9.144-3.dsc linux-headers-4.9.0-8-amd64 linux-kbuild-4.9
# tar xJf linux_4.9.144.orig.tar.xz
$ vim linux-4.9.144/drivers/tty/sysrq.cНайдите функцию sysrq_handle_crash:
static void sysrq_handle_crash(int key)
{
char *killer = NULL;
/* we need to release the RCU read lock here,
* otherwise we get an annoying
* 'BUG: sleeping function called from invalid context'
* complaint from the kernel before the panic.
*/
rcu_read_unlock();
panic_on_oops = 1; /* force panic */
wmb();
*killer = 1;
}И что важнее, взгляните на 144 строку:
*killer = 1;Это строка, которая привела к ошибке из-за отсутствия страницы на строке #6 в трассировке стека падения ядра Linux:
#6 [ffffa67440b23dc0] page_fault at ffffffffa121a618Итак, теперь вы знаете основы отладки плохого кода ядра, но что случится, если вы захотите отладить свой собственный модули ядра Linux (к примеру, драйверы)? Я написал простой модуль ядра Linux, который приводит к похожему падению ядра при загрузке. Сохраните его в файл test-module.c где-нибудь в вашей домашней папке.
#include <linux/init.h>
#include <linux/module.h>
#include <linux/version.h>
static int test_module_init(void)
{
int *p = 1;
printk("%d\n", *p);
return 0;
}
static void test_module_exit(void)
{
return;
}
module_init(test_module_init);
module_exit(test_module_exit);Вам нужен Makefile для компиляции модуля ядра (сохраните его в той же папке):
obj-m += test-module.o
all:
$(MAKE) -C/lib/modules/$(shell uname -r)/build M=$(PWD)Запустите команду make для компиляции модуля, но не удаляйте никаких артефактов сборки (они понадобятся вам далее):
$ makeЗамечание: вы можете увидеть предупреждения компилятора при сборке. Проигнорируйте их. Эти предупреждения указывают именно на то, что и приведёт к падению ядра в дальнейшем.
Теперь будьте осторожны, когда вы загрузите .ko файл система упадёт, поэтому убедитесь что всё сохранили и синхронизировали данные на диске:
# sync && insmod test-module.koКак и раньше, произойдёт паника ядра, а kexec сохранит всю информацию где-то в какой-нибудь подпапке /var/crash, после чего система перезагрузится. После загрузки системы в рабочем состоянии, найдите папку с аварийными файлами и перейдите в неё:
$ cd /var/crash/201902271035/Кроме того, скопируйте в неё объектный файл test-module из своей домашней дериктории:
# cp ~/test-module.o /var/crash/201902271035/Загрузите аварийный файл для отладки:
# crash dump.201902271035 /usr/lib/debug/vmlinux-4.9.0-8-amd64Обзор падения будет выглядить как-то так:
KERNEL: /usr/lib/debug/vmlinux-4.9.0-8-amd64
DUMPFILE: dump.201902261035 [PARTIAL DUMP]
CPUS: 4
DATE: Tue Feb 26 10:37:47 2019
UPTIME: 00:11:16
LOAD AVERAGE: 0.24, 0.06, 0.02
TASKS: 102
NODENAME: deb-panic
RELEASE: 4.9.0-8-amd64
VERSION: #1 SMP Debian 4.9.144-3 (2019-02-02)
MACHINE: x86_64 (2592 Mhz)
MEMORY: 4 GB
PANIC: "BUG: unable to handle kernel NULL pointer
↪dereference at 0000000000000001"
PID: 1493
COMMAND: "insmod"
TASK: ffff893c5a5a5080 [THREAD_INFO: ffff893c5a5a5080]
CPU: 3
STATE: TASK_RUNNING (PANIC)Причина падения ядра описана как: BUG: unable to handle kernel NULL pointer dereference at 0000000000000001. Команда пользователя, которая привела к падению, была insmod.
В трассировке стека функций падения можно найти исключение из-за отсутсвие страницы по адресу ffffffffc05ed005:
crash> bt
PID: 1493 TASK: ffff893c5a5a5080 CPU: 3 COMMAND: "insmod"
#0 [ffff9dcd013b79f0] machine_kexec at ffffffffa3a53f68
#1 [ffff9dcd013b7a48] __crash_kexec at ffffffffa3b086d1
#2 [ffff9dcd013b7b08] crash_kexec at ffffffffa3b08738
#3 [ffff9dcd013b7b20] oops_end at ffffffffa3a298b3
#4 [ffff9dcd013b7b40] no_context at ffffffffa3a619b1
#5 [ffff9dcd013b7ba0] __do_page_fault at ffffffffa3a62476
#6 [ffff9dcd013b7c10] page_fault at ffffffffa401a618
[exception RIP: init_module+5]
RIP: ffffffffc05ed005 RSP: ffff9dcd013b7cc8 RFLAGS: 00010246
RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000000000000000
RDX: 0000000080000000 RSI: ffff893c5a5a5ac0 RDI: ffffffffc05ed000
RBP: ffffffffc05ed000 R8: 0000000000020098 R9: 0000000000000006
R10: 0000000000000000 R11: ffff893c5a4d8100 R12: ffff893c5880d460
R13: ffff893c56500e80 R14: ffffffffc05ef000 R15: ffffffffc05ef050
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#7 [ffff9dcd013b7cc8] do_one_initcall at ffffffffa3a0218e
#8 [ffff9dcd013b7d38] do_init_module at ffffffffa3b81531
#9 [ffff9dcd013b7d58] load_module at ffffffffa3b04aaa
#10 [ffff9dcd013b7e90] SYSC_finit_module at ffffffffa3b051f6
#11 [ffff9dcd013b7f38] do_syscall_64 at ffffffffa3a03b7d
#12 [ffff9dcd013b7f50] entry_SYSCALL_64_after_swapgs at ffffffffa401924e
RIP: 00007f124662c469 RSP: 00007fffc4ca04a8 RFLAGS: 00000246
RAX: ffffffffffffffda RBX: 0000564213d111f0 RCX: 00007f124662c469
RDX: 0000000000000000 RSI: 00005642129d3638 RDI: 0000000000000003
RBP: 00005642129d3638 R8: 0000000000000000 R9: 00007f12468e3ea0
R10: 0000000000000003 R11: 0000000000000246 R12: 0000000000000000
R13: 0000564213d10130 R14: 0000000000000000 R15: 0000000000000000
ORIG_RAX: 0000000000000139 CS: 0033 SS: 002bДавайте посмотри на символ по адресу ffffffffc05ed005:
crash> sym ffffffffc05ed005
ffffffffc05ed005 (t) init_module+5 [test-module]Хммм. Причина падения случилась где-то в коде инициализации драйвера ядра test-module. Но что случилось со всеми теми деталями, которые были в предыдущем анализе? Так как этот код не часть отладочного образа ядра, нужно найти способ загрузить его в текущий анализ падения. Вот почему выше был скопирован объектный файл модуля в текущую директорию. Сейчас пришло время загрузить этот объектный файл:
crash> mod -s test ./test.o
MODULE NAME SIZE OBJECT FILE
ffffffffc05ef000 test 16384 ./test-module.oВернёмся назад и посмотрим символ по адресу ещё раз:
crash> sym ffffffffc05ed005
ffffffffc05ed005 (T) init_module+5 [test-module] /home/ozi/test-module.c: 8Теперь можно вернуться к исходному коду файла test-module.c и посмотреть на 8 строчку:
$ sed -n 8p test-module.c
printk("%d\n", *p);Так и есть, ошибка загрузки страницы произошла, когда вы пытались разыменовать плохой указатель. Помните предупреждения компилятора? Это касалось как раз этой проблемы, и эта же проблема привела к панике ядра. Возможно, мы сможем написать код получше в будущем =)
Что ещё вы можете сделать здесь?
Файл падения ядра содержит много данных о вашей системе в момент ошибки. Вы можете посмотреть список доступных команд введя help:
crash> help
* files mach repeat timer
alias foreach mod runq tree
ascii fuser mount search union
bt gdb net set vm
btop help p sig vtop
dev ipcs ps struct waitq
dis irq pte swap whatis
eval kmem ptob sym wr
exit list ptov sys q
extend log rd taskК примеру, можно посмотреть обзор использования памяти:
crash> kmem -i
PAGES TOTAL PERCENTAGE
TOTAL MEM 979869 3.7 GB ----
FREE 835519 3.2 GB 85% of TOTAL MEM
USED 144350 563.9 MB 14% of TOTAL MEM
SHARED 8374 32.7 MB 0% of TOTAL MEM
BUFFERS 3849 15 MB 0% of TOTAL MEM
CACHED 0 0 0% of TOTAL MEM
SLAB 5911 23.1 MB 0% of TOTAL MEM
TOTAL SWAP 1047807 4 GB ----
SWAP USED 0 0 0% of TOTAL SWAP
SWAP FREE 1047807 4 GB 100% of TOTAL SWAP
COMMIT LIMIT 1537741 5.9 GB ----
COMMITTED 16370 63.9 MB 1% of TOTAL LIMITИли же посмотреть актуальный лог dmesg при падении:
crash> log
[ 0.000000] Linux version 4.9.0-8-amd64 (debian-kernel@lists.debian.org) (gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1) ) #1 SMP Debian 4.9.144-3 (2019-02-02)
[ 0.000000] Command line: BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-a0d8-a7533620f6fa ro quiet crashkernel=128M
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
[ 0.000000] x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
[ .... ]Используя утилиту crash, можно ещё глубже детализировать области памяти и их содержимое, узнать что обрабатывалось на каждом ядре процессора и многое другое. Если вы хотите узнать больше об этих функция, просто введите help имя_комманды:
crash> help swapЗаключение
Это очень поверхностное введение в отладку ядра, оно охватывает лишь основы. Но, надеюсь, оно станет для вас отправной точкой для диагностики ошибок ядра в продакшен, тестовых и рабочих окружениях.